- GPU Shared Intel Memory Benefits LLMS
- The VRAM extended pools allow a more fluid execution of the workloads of the AI
- Some games slow down when memory is developing
Intel has added a new capacity to its main ultra systems that echoes an earlier movement of the DMLA.
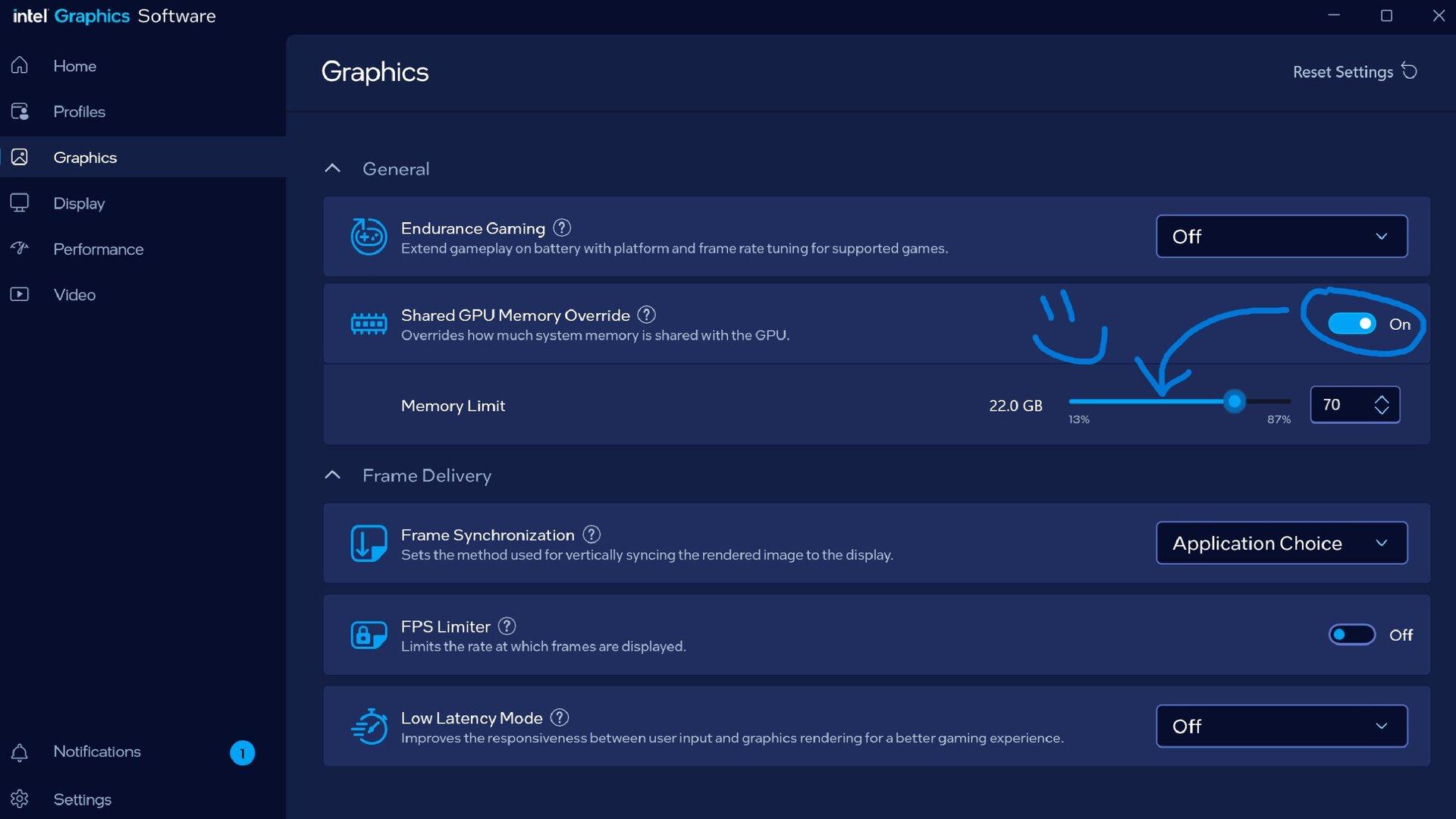
The functionality, known as “Shared GPU memory replacement”, allows users to allocate an additional RAM system to be used by integrated graphics.
This development is targeted on the machines based on integrated solutions rather than discreet GPUs, a category that includes many compact laptops and mobile workstation models.
Memory allocation and game performance
Bob Duffy, who directs the graphics and the evangelization of AI at Intel, confirmed the update and indicated that the last Intel Arc pilots are necessary to allow the function.
Change is presented as a means of improving the flexibility of the system, in particular for users interested in the tools and workloads of AI which depend on the availability of memory.
The introduction of additional shared memory is not automatically an advantage for each application, because the tests have shown that some games can load larger textures if more memory is available, which can really cause performance to dive rather than improve.
The anterior “variable graphic memory” of AMD has been largely framed as an improvement in games, especially when combined with AFMF.
This combination made it possible to store more game active ingredients directly in memory, which sometimes produced measurable gains.
Although the impact was not universal, the results varied according to the software in question.
Intel adoption of a comparable system suggests that it is eager to remain competitive, although skepticism remains on the way it will benefit daily users.
Although players can see mixed results, those working with local models could bear to earn more from Intel’s approach.
The execution of large local language models is becoming more and more common, and these workloads are often limited by available memory.
By extending the RAM pool available for integrated graphics, Intel positions its systems to manage the larger models which would be otherwise forced.
This can allow users to discharge more models on VRAM, reducing the bottlenecks and improving stability when executing AI tools.
For researchers and developers without access to a discreet GPU, this could offer a modest but useful improvement.


