- Sonos adds an option to improve speech AI to the ultra arc
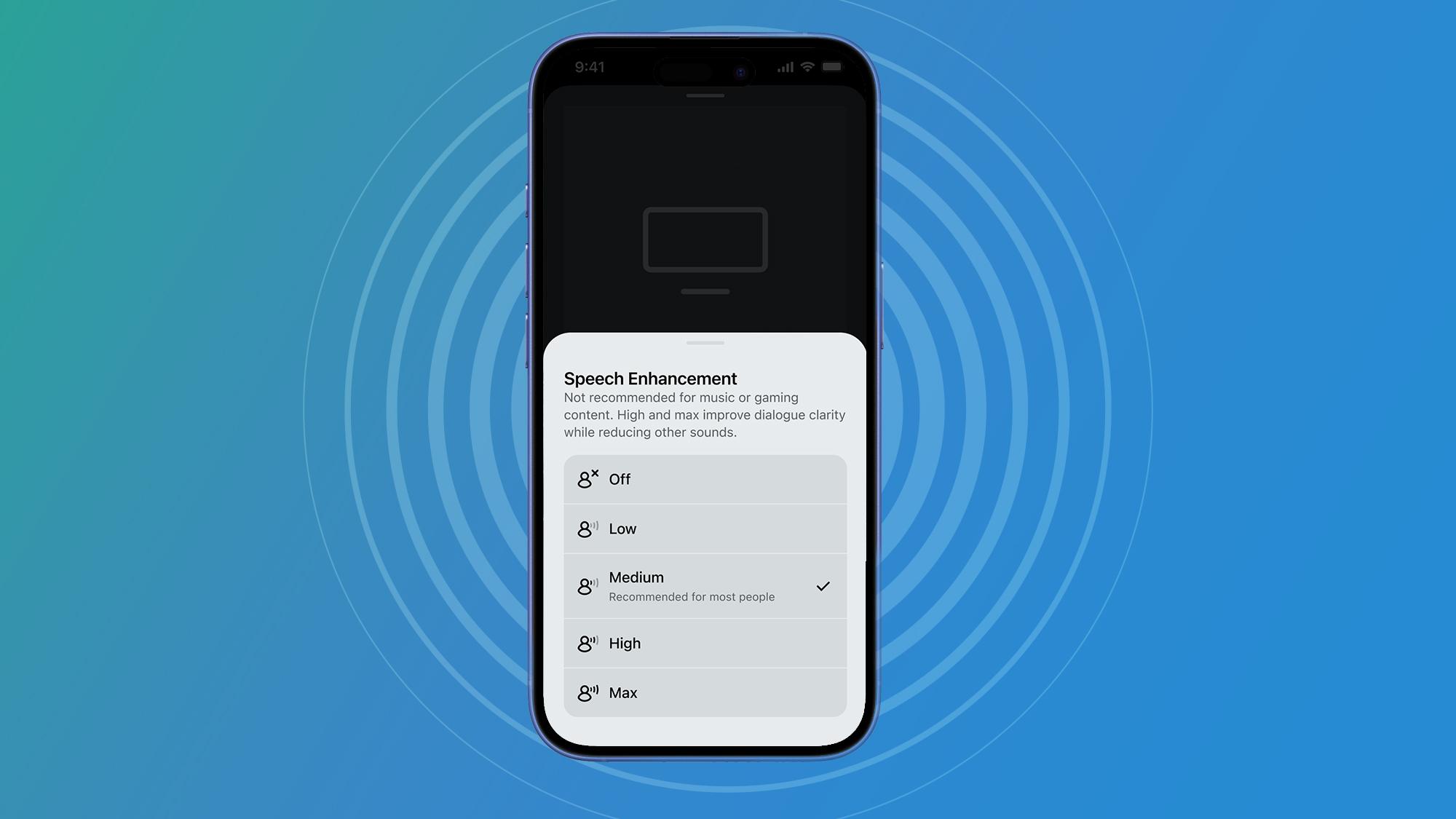
- This is the first sound characteristic of Sonos AI, with four levels of speech boost
- It was developed with a hearing aid organization to help people with hearing loss
Sonos has launched a new version of its speech improvement tools for the Sonos Arc Ultra, which we assess as one of the best bars of its available.
You will always find these tools on the Playing Now screen in the Sonos application, but instead of having just a few options, you will now have four new modes (low, medium, high and maximum), all fed by the first use by the company of an AI sound processing tool. They should be available today (May 12) to all users.
These modes were developed in a one -year partnership with the Royal National Institute for the Deaf (RNID), the main British charitable organization for people with hearing loss. I spoke to Sonos and the RNID to obtain the interior history on its development here – but you can read here for more details.
The update will be launched today on the bars of its ultra Sonos Arc, but will not be available on any other sound bar, because it requires a higher level of processing power, that the chip inside the ultra arc can provide, but the oldest bars of its cannot.
The AI element is used to analyze the sound crossing the sound bar in real time, and separate the elements from the “word” of the sound so that they can be made more important in the mixture without affecting the rest of the sound. I heard it in the action during a demo to the installation of product development in the United Kingdom of Sonos, and it is very impressive.
If you have already used speech improvement tools, you are probably familiar to hear the dynamic beach of sound, and in particular the bass, suddenly reduced massively in exchange for elements of speech which are pushed further.
This is not the case with the new sound mode – powerful bass, the global sound landscape and the most immersive Dolby Atmos elements are all much better maintained. It is for two reasons: one is that the discourse is improved separately with other parts, and the other is that it is a dynamic system which only activates when it detects that speech is likely to be drowned by background noise.
This will not activate if the dialogue occurs in a silent background, or if there is no dialogue in the scene. And it is a system that works by degrees – it applies more treatment in the busiest scenes, and less when the audio is not as chaotic.
How does it sound?
On the two lowest modes, the dialogue is chosen more clearly without any major damage to the rest of the soundtrack, based on my demo.
In high mode, the background was always very well maintained, but the speech began to seem a little more treated, and on max, I could hear the background to be pouring a little the wings, and a little more artificiality for the speech-but the speech was extremely well chosen, and this mode is only really designed for the hard to hear.
I mentioned that the mode was developed with the RNID, which involved Sonos consulting solid research experts at the RNID, but also people with different types and levels of hearing loss to test the modes with different stages of development and provide feedback.
I spoke for a long time to the architects Sonos Audio and AI who developed the new modes, as well as the RNID, but the key to remember is that the collaboration has led Sonos to put more emphasis on the conservation of the immersive sound effects and the addition of four levels of improvement instead of the three.
Despite the participation of the RNID, the new mode is not designed to be only for the hard hearing. It is always called the improvement of speech, as it is now, and it is not hidden as an accessibility tool – sound is improved for everyone, and “everyone” understands people with a light to moderate hearing loss better. Low and means modes can also work for those of us who need a little additional clarity in the occupied scenes.
It is not the first use of the separation of speech fueled by the AI that I saw – I experienced it on Samsung TVS, and in a fun window of Philips TVS, where it was used to deactivate the comment during sport but preserve the sounds of the crowd.
@Techradar ♬ Sound Original – Techradar
But it is interesting that this is the first use of sound processing of Sonos AI, and the development process of four years, including a year of refinement with the RNID, shows that Sonos has adopted a thoughtful approach to the way it is the best used that is not always easy in other AI sound processing applications. Here is my article interviewing AI and audio developers of Sonos with RNID researchers.
It’s just a shame that it is exclusive to the ultra Arc Sonos for the moment – although I’m sure the new versions of Sonos Ray and Sonos Beam Gen 2 will be for too long with the same improved chip to support functionality.


