- The hyperlink works entirely on local hardware, keeping each search private
- App indexes large data folders on RTX PCs in minutes
- LLM Inference on Hyperlink Doubles in Speed with Latest Nvidia Optimization
Nexa.ai’s new “Hyperlink” agent introduces an AI search approach that runs entirely on local hardware.
Designed for Nvidia RTX AI PCs, the app functions as an on-device assistant that transforms personal data into structured information.
Nvidia explained how, instead of sending requests to remote servers, it processes everything locally, providing both speed and privacy.
Private intelligence at local speed
Hyperlink was evaluated on an RTX 5090 system, where it reportedly delivers up to 3x faster indexing and 2x the large language model inference speed compared to previous versions.
These measurements suggest that it can analyze and organize thousands of files on a computer more efficiently than most existing AI tools.
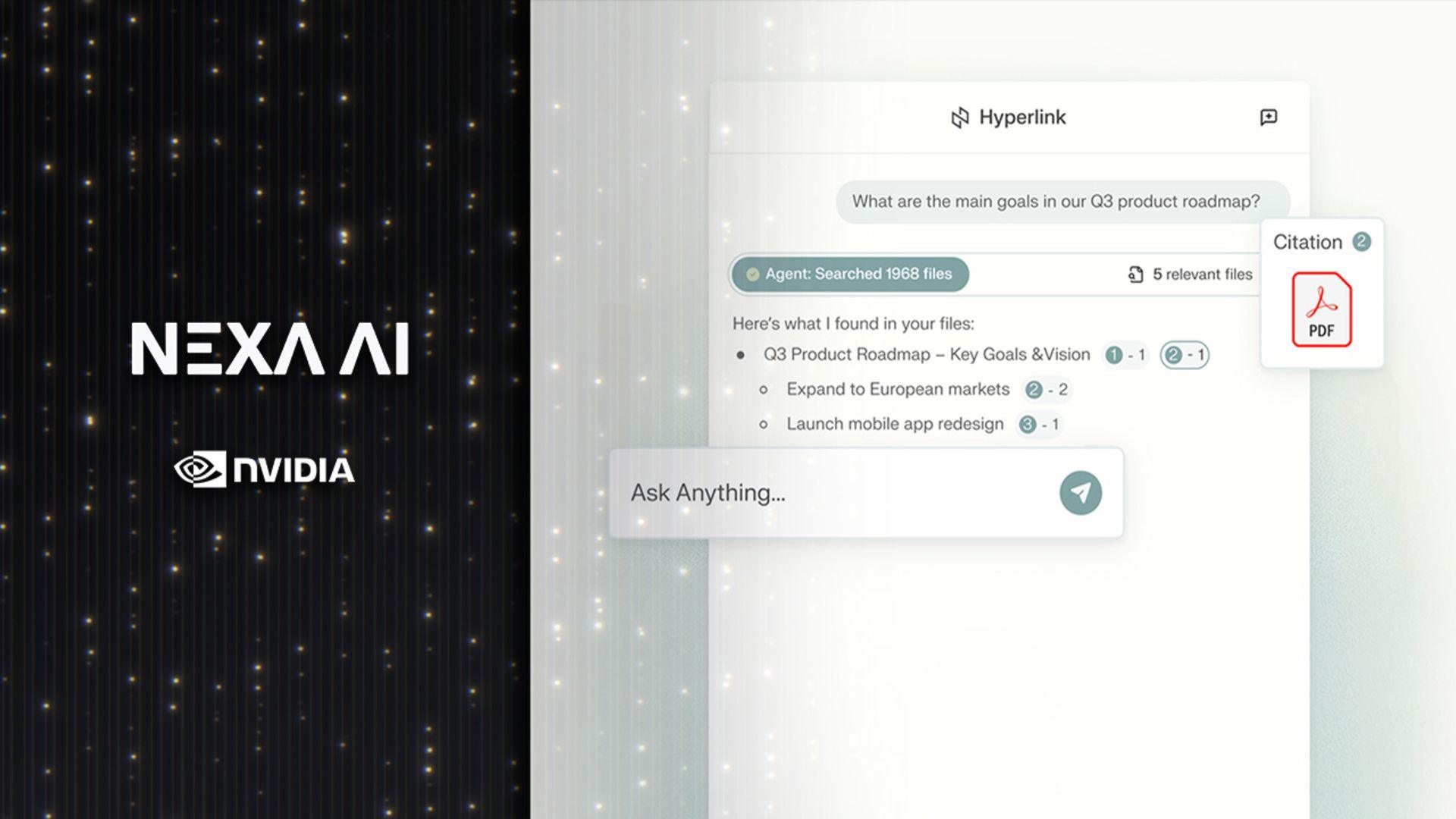
The hyperlink does not simply match search terms, because it interprets user intent by applying the reasoning capabilities of LLMs to local files, allowing it to locate relevant material even when file names are obscure or unrelated to the actual content.
This shift from static keyword search to contextual understanding aligns with the growing integration of generative AI into everyday productivity tools.
The system can also link related ideas from multiple documents, providing structured answers with clear references.
Unlike most cloud-based assistants, Hyperlink keeps all user data on the device, so the files it analyzes, ranging from PDFs and slides to images, remain private, ensuring that no personal or confidential information leaves the computer.
This model appeals to professionals dealing with sensitive data who still want to benefit from the performance advantages of generative AI.
Users have access to rapid contextual responses without the risk of data exposure that comes with remote storage or processing.
Nvidia’s optimization for RTX hardware extends beyond search performance, as the company says Fetch Augmented Generation (RAG) now indexes dense data folders up to three times faster.
A typical 1 GB collection that once took almost 15 minutes to process can now be indexed in about 5 minutes.
Improving inference speed also means answers appear faster, making everyday tasks such as preparing for meetings, study sessions, or analyzing reports smoother.
Hyperlink combines convenience and control by combining local reasoning and GPU acceleration, making it a useful AI tool for people who want to keep their data private.
Follow TechRadar on Google News And add us as your favorite source to get our news, reviews and expert opinions in your feeds. Make sure to click the Follow button!
And of course you can too follow TechRadar on TikTok for news, reviews, unboxings in video form and receive regular updates from us on WhatsApp Also.


